Mysql 表分区实践
为什么要分区
单表数据量过大时,查询操作会导致 CPU 飙升,机器压力很大,所以 Mysql 官方开发了分区功能,可以用来解决这个问题。
Mysql 的分区原理
分区就相当于把原先存在一张表中的数据,按照指定规则放到几张小表里,当查询进来后再按照这个规则去找对应的表。比如按照区间分表,把用户 id 0-100000 的放到一个表,100000-200000 的放一个表,一般是根据业务来定规则。
分区的策略
Range Partition
按照某个字段的区间来分,比如说按照store_id区间分,stroe_id 在 [0,6] [6,11] [11,16] [16,21] 这些区间分属于不同的区域
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
List Partition
按照某个字段是否属于一个离散区间内的一个给定值来区分,比如说 store_id 在 (3,5,6,9,17) (1,2,10,11,19,20) (4,12,13,14,18) (7,8,15,16) 这些集合中分属于不同的分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
HASH partitioning
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。比如根据员工受雇年份来区分,我要把它分成 4 个分区,
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY HASH( YEAR(hired) ) PARTITIONS 4;KEY partitioning
基于某一个字段进行分区,类似 Hash 分区,有区别的地方是可以指定多个列当key,可以把字符串列当 key,如果表字段中有主键的话必须指定主键为 key
CREATE TABLE foo_key ( empno VARCHAR(20) NOT NULL , empname VARCHAR(20), birthdate DATE NOT NULL ) PARTITION BY KEY(birthdate, empname) PARTITIONS 4;
分区实践
环境 Ubuntu 16.04 Mysql 8.0.15 创建一张没有分区的表
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL COMMENT '余额',
`cid` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `cid` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=8912744 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
创建一张有分区的表
CREATE TABLE `account_partition` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL COMMENT '余额',
`cid` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `cid` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=8912744 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (2000000),
PARTITION p1 VALUES LESS THAN (4000000),
PARTITION p2 VALUES LESS THAN (6000000),
PARTITION p3 VALUES LESS THAN (8000000),
PARTITION p4 VALUES LESS THAN (10000000)
);
然后每个表插入8388608行数据(我使用的方法是insert into select)
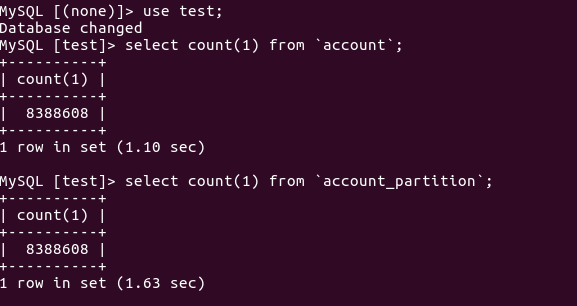
对比下使用了分区和没有使用分区的查询情况
SELECT * FROM `account` WHERE `id` = 5000000;
SELECT * FROM `account_partition` WHERE `id` = 5000000;
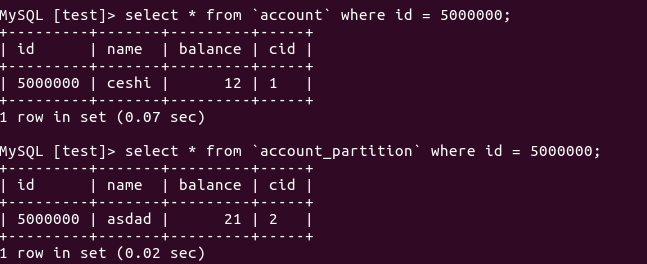
SELECT * FROM `account` WHERE `id` = 2000000;
SELECT * FROM `account_partition` WHERE `id` = 2000000;
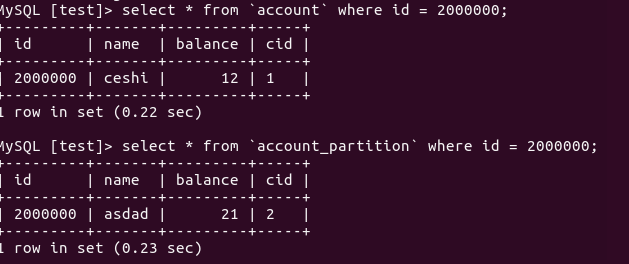
SELECT * FROM `account` LIMIT 5000000,10;
SELECT * FROM `account_partition` LIMIT 5000000,10;
这组数据有些意思,值得深究一下,为什么分区的反而比没分区的快
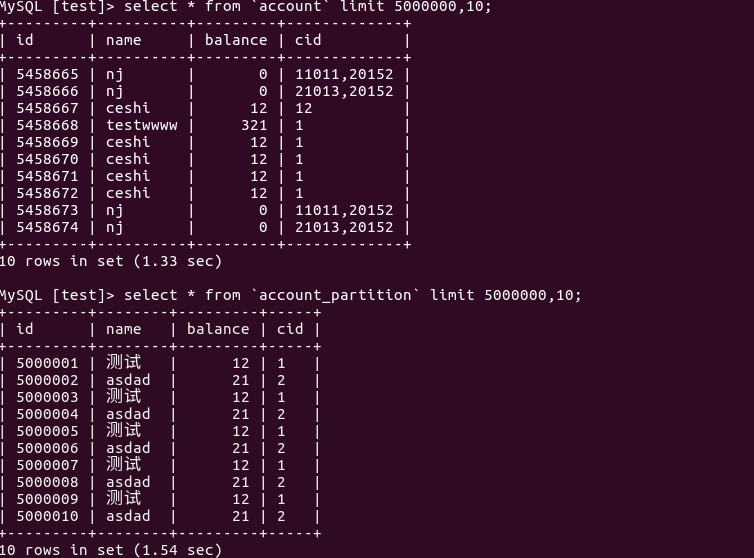
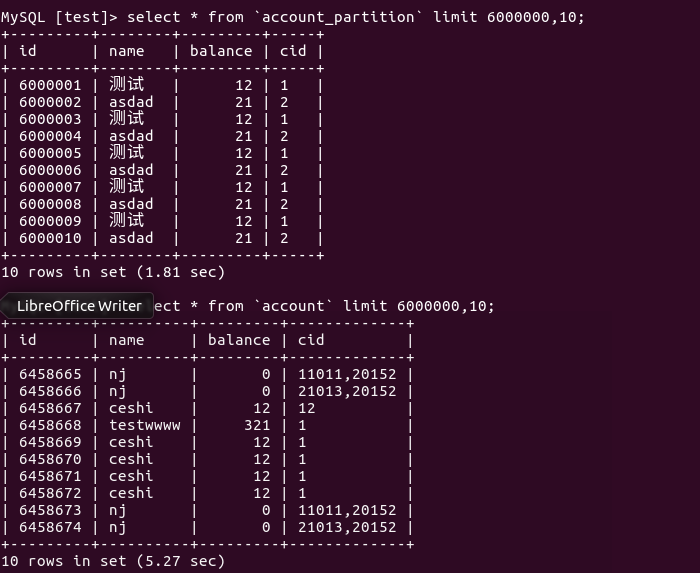
SELECT * FROM `account` LIMIT 6000000,10;
SELECT * FROM `account_partition` LIMIT 6000000,10;
Mysql 分区的坑
- 分区表,分区键设计不太灵活,如果不走分区键,很容易出现全表锁
- 一旦数据量并发量上来,如果在分区表实施关联,就是一个灾难
- 自己分库分表,自己掌控业务场景与访问模式,可控。分区表,研发写了一个sql,都不确定mysql是怎么玩的,不太可控
- Mysql 8.0 只支持 Innodb 和 NDB 分区
参考资料
1. partitioning-types